We all know that when a visual display is too cluttered, it takes longer to retrieve the information we desire and even if we could locate the information eventually, the cluttered environment might also impact the quality of the information we retrieve. This paper by Stefano Baldassi and others from Firenze, Italy (published in 2004) investigated how such visual clutter affect the quality of perceptual decisions, and came to the conclusion that
... perceptual clutter leads not only to an increase in judgment errors, but also to an increase in perceived signal strength and decision confidence on erroneous trials.
In other words, the more visual clutters we have, the more mistakes the user tends to make, and he is also more stubborn about it. Hmm, interesting!!
The researchers performed an interesting experiment and focused on how visual clutter could affect people's perception of orientation. Each user is shown very briefly (100 ms) a picture of various number of icons like the one shown below where one of them is tiled slightly and the others are all vertical. The user is then asked to describe the direction and magnitude of the tilt by either selecting one of 12 tilted icons of various degrees (in sorted order) on the screen, or manually rotating a big icon using the mouse. The user also has to specify how confident he is by marking icons of various sizes, where the sizes of the icons represent levels of confidence.
Figure 1 in the paper illustrating the experiment sequence
Experimental results show that under conditions of visual clutter people tend to perceive stimuli to be more strongly tiled when they were wrong about the tilting directions. To make sure this was not caused by low-level sensory interactions between adjacent stimuli when close proximity occurs as the number of icons increase, a technique of "partial cueing" was used, and the results showed similar trends. Confidence ratings reported by users also show that average confidence is significantly higher as icon set size increases.
To illustrate the practicality of the findings, the authors presented a fun example:
For example, soccer referees are frequently required to decide rapidly whether a player is "offside" if the ball is passed to him when there are no defenders (besides the goalkeeper) between him and the goal. this study predicts that when there are several candidate defenders that could place the forward onside, the decision will not only be more error-prone, but the confidence with which referees call their (often erroneous) decisions will be higher.
Argentina's goal against Germany disallowed because of offside. There was plenty of audio clutter (the vuvuzelas), but I guess there was still not enough visual clutter here! Alas!
The user study the authors performed is really a pilot study with only ten users (including the authors). Too better validate the findings, a more extensive user study of more human subjects of various age, profession, etc. is probably necessary. I am also curious about whether adding more types of distractors (such as circle icons without line in the middle) would affect the results. Another one to try would be comparing same number of icons that are spaced very tightly versus sparsely (another dimension of clutter).
The paper ended with a quote from John Kerry in the first 2004 debate, which I found quite amusing, I'll also use it to end this post:
It's one thing to be certain, but you can be certain, and you can be wrong. Certainty sometimes can get you into trouble.
Videos of the Day:
Paul, the German psychic octopus, has become a world-wide superstar after it correctly predicted the outcomes of all six of Germany's games in the 2010 South Africa World Cup, including Germany's latest defeat in the semi-final against Spain. Since then, disgruntled German football fans have been sending death threats to the owner and the octopus suggesting a grilled octopus dinner.
With one more game to play for the German team fighting for the third place in the tournament against Uruguay tomorrow, the "Oracle Octopus" spoke again, predicting a German win, but one must wonder weather this has been influenced by the fear of ending up on a sushi menu. Tabarez, the Uruguay coach, however, vowed to beat Germany and the octopus at the same time! Well, may the better team win!
This paper was written by Hanjoon Kim and Sanggoo Lee from Seoul National University presented at the ninth international conference on Information and knowledge management, 2000.
Traditional document clustering methods are unable to correctly discern structural details hidden within the document corpus because they inherently strongly depend on the document themselves and their similarity to each other. To solve this problem, this paper proposes a clustering method that incorporates relevance feedback into a traditional complete-linkage clustering algorithm in order to find more coherent clusters.
The main contribution of this paper is the method of combining complete-linkage hierarchical agglomerative clustering (HAC) algorithm using the VSM model with user relevance feedback using the fuzzy information retrieval. The HAC with VSM allows the forming of pre-clusters using a “fixed-diameter”. Then documents in small clusters (less than η) form a “training document set”, which is used for user relevance feedback where user can answer “yes/no” questions to indicate relevance of documents returned using fuzzy information retrieval. This way, positive and negative bundles can be created and used to help reassign pre-clusters. Note that all these techniques mentioned above are not original ideas from the authors. The paper simply proposed a way to combine the strengths of these techniques in order to improve performance of the clustering.
Toward the end of the paper, the authors included two subsections that discuss the sensitivity of the degree of supervision parameter and the pre-cluster size parameter (“fixed-diameter”). This is a good attempt to justify the “magic numbers” used in the experiments. However, there is no discussion or analysis of the parameter η used in the supervising phase at all. Also, the paper describes that, “the threshold diameter value for pre-clusters is experimentally adjusted to provide good quality clustering.” This makes the reader wonder whether the experimental results presented are truthful and question how well the proposed method would work in real world applications.
Clustering techniques are used to group together things that have common themes. However, frequently, there are many different ways to group things based on different common themes and the distance function used decides what common theme will be used for the clustering. For example, a bunch of people can be grouped by one of many themes (e.g. age, gender, race, wealth, and hair style). Similarly, a document collection can also be clustered by themes such as style, topic, language, or subject. The paper simply stated the two alternative ways to define the diameter of a cluster but didn’t analyze how such selections might affect the results of the document clustering. The paper also did not clarify which definition of the diameter is used in the experiments.
The authors mentioned in several places that the proposed method helps in discerning structural details hidden within documents. However, throughout the paper, there is no discussion about how structural details are extracted from documents. Arguably the users might be able to identify structural details through user relevance feedback. However, this really has nothing to do with the proposed algorithm. The users might not even be looking at the structural detail of these documents at all.
A core part of the proposed method relies on human to provide domain-specific knowledge for the method to work, yet the paper is missing detailed description of how the experiment was designed to incorporate human knowledge. For example, we don’t know how many human analysts are involved. Could the human analysts have different opinions? If so, how is that handled? Are these human analysts really domain experts who possess domain-specific knowledge about the subject? The paper is also missing detailed description about how the queries are reformulated, which is an integral part of the user relevance feedback method.
In the supervising phrase, the user is asked to answer “yes/no” questions to mark documents as relevant to non-relevant to the query document. Firstly, relevance is a subjective question. It is possible that document marked as relevant by one user might end up being marked as non-relevant by another user. Secondly, a binary answer completely ignores the level of relevance (ranking). This results in that documents border lining non-relevance could still be marked as relevant and have the same weight as the most relevant document. This leads to inaccuracy and misrepresentation. A non-binary weighting probably would work better.
When building the test document set, the authors intentionally picked those that had a single topic, claiming that this would avoid the ambiguity of documents with multiple topics. Is this really for technical convenience so the experiment results would look better? Does this mean the proposed method would not work well at all for documents with multiple topics (which is probably more like the real world scenarios)?
The authors used F1-measure as the performance metric and used the complete-linkage clustering method as a baseline. The baseline selected is reasonable in order to show how much benefit can be achieved by adding the user relevance feedback component. However, using this baseline alone is not very convincing because we already know the complete-linkage clustering method doesn’t work well, and we also know that adding user relevance feedback will certainly help. It would be much more convincing if the paper compared the performance of the proposed method with another common document clustering technique such as K-Means and Bisecting K-Means. Using only the F1-measure as the performance metric is also weak. Including other quantitative metrics together with some qualitative analyses would certainly help.
In summary, this paper proposes a novice approach that combines the strengths of several IR techniques. However, it also has plenty of room for improvement.
Picture of the Day:
The biggest failure of the 2010 World Cup -- Domenech! We still wonder, "Why not Henry and why not Malouda?"
This paper was written by Comaniciu and Meer of Rutgers University presented at International Conference on Computer Vision 99.
In order to avoid estimation of the probability density function, mean shift is applied as a nonparametric estimator of density gradient. In image segmentation as well as smoothing process, it’s difficult to keep details while merge similar parts solely by spatial domain or range domain solutions. Usually users are required to set many constraint parameters for these tasks.
This paper proves the convergence of mean shift on lattices, and employs mean shift in the joint, spatial-range domain of gray level and color images for discontinuity preserving filtering and image segmentation. In processing in Spatial-Range Domain, each data point becomes associated to a point of convergence which represents the local mode of the density in the d-dimensional space. The output of the mean shift filter for an image pixel is defined as the range of information carried by the point of convergence. For the segmentation task, the convergence points sufficiently close in the joint domain are fused to obtain the homogeneous regions in the image. And for smoothing task, these points are merged together.
Mean-shift applied to several videos by someone somewhere (not me).
Based on proof of the convergences and applications in image smoothing and segmentation, mean shift can merge similar regions while keeping high details at the same time. Also this method reduces parameters needed for these tasks. What is more, the mean shift has a more powerful adaptation to the local structure of the data, and can run until convergence without stopping criterion.
Picture of the Day:
The differences between the World Cup and the Ph.D., (credit: http://www.phdcomics.com).
This paper was written by Meila (MIT) and Heckerman (Microsoft Research) and published at the Machine Learning journal in 2001.
This tech report compares three batch clustering algorithms: EM, CEM, and HAC and also investigate the effect of three different initialization schemes on the final solution produced by the EM algorithm.
The clustering algorithms first use the log posterior probability of model structure given the training data log P(K|Dtrain) to select model structure, and then learn the parameters of a given model structure. The EM algorithm is iterative, and in the E step, assigns the case fractionally to each cluster. The CEM algorithm assigns the case fully to the class k that has the highest posterior probability given the document and the current parameter values. The HAC algorithm merge smaller clusters by recursively merging the two clusters that are closest together until only K clusters are left. The authors derive the distance metric for mixtures of independent multinomially distributed variables.
The three initialization methods experimented are: the random approach where the parameters are independent of the data, the noisy-marginal method (data dependent), and the method of using HAC on a random sample of the data. Several performance criteria are used. For the model structure, the log-marginal-likelihood criterion and the difference between the number of clusters in the model and the true number of clusters are used. For the entire model, one criterion is the cross entropy between the true joint distribution for X and the joint distribution given by the model, and another criterion is the classification accuracy. Running time is also used to compare algorithms.
Experimental results from two datasets were reported. The synthetic dataset was constructed using the MSNBC news service, and the digits dataset consists of images of handwritten digits made available by the US Postal Service Office for Advanced Technology. For both datasets, EM outperformed CEM for all initialization methods and for all criteria (except that CEM is four times faster than EM). After constraining EM run time to match CEM, EM still performed better. When comparing EM versus HAC (initializing using Marginal method), EM is clearly better.
When comparing initialization methods, for the Synthetic dataset, Marginal and HAC are always better than Random (for all criteria) with no significant differences between themselves, but Marginal is much faster than HAC. For the digit6 dataset, there is no clear winner.
Picture of the Day:
First time ever a rescue helicopter landing in Bryce Canyon, Utah. The chopper landed right on the top of the ridge. Got to give the pilot some shout out for his awesome skills!
This paper is written by Steinback, Karpis, and Kumar, University of Minnesota, published at KDD workshop on text mining, 2000.
This paper presents the results of an experimental study of two main approaches to document clustering, agglomerative hierarchical clustering and K-means (standard K-means and bisecting K-means).
Example of Hierarchical Agglomerative Clustering (HAC)
The two basic approaches to generating a hierarchical clustering are agglomerative and divisive. The paper evaluated agglomerative techniques in the comparison. It then described the agglomerative clustering algorithm, the K-means algorithm, and the bisecting K-means algorithm in details.
Visualization of the K-means algorithm
Three evaluation metrics are used in the experiments, and they include two external quality measure, entropy, F measure, and one internal quality measure, overall similarity. The paper described each measure in detail.
Eight data sets were used in the experiments: 5 from TREC, 2 from Reuters-21578, and 1 from WebACE. Performances of three agglomerative hierarchical techniques, Intra-Cluster Similarity Technique (IST), Centroid Similarity Technique (CST), and UPGMA were compared using F-measure and entropy. UPGMA is the best performing hierarchical technique overall, therefore, its performance is compared against standard K-means and bisecting K-means. The performances of bisecting K-means with refinement and hierarchical with refinement are also included in the comparison. In the experiments, the authors used many runs of the regular K-means algorithm and also used incremental updating of centroids.
Experimental results show that the bisecting K-means technique is better than the standard K-means approach and as good or better than the hierarchical approaches when using the three evaluation metrics mentioned. Also the time complexity of bisecting K-means is linear, which makes it very attractive.
The authors argued that the agglomerative hierarchical clustering didn’t do well because nearest neighbors of documents often belong to different classes. K-means and bisecting K-means algorithms do better because they rely on a more global approach. They also believe that bisecting K-means does better than standard K-means because it produces relatively uniformly sized clusters.
Video of the Day:
The Honest $10000 SPAM
Even though miracle happens, still, don't click on suspicious links or give out your bank information. The Nigerian connection at the end of the video is simply hilarious!!
This paper was written by Thorsten Joachims from University Dortmund. It was published at ECML-98 10th European Conference on Machine Learning. It has been cited by 3632 people according to Google Scholar. Very influential paper indeed!
This paper provides both theoretical and empirical evidence that SVMs are great for text categorization.
When performing text classification, the first step is to transform documents. Each distinct word becomes a feature and the frequency of the word in the document is the value of the feature, resulting in a very high-dimensional feature space. Then, the information gain criterion can be used to select a subset of features. The final step is to scale the dimensions of the feature vector with their inverse document frequency.
SVMs are very universal learners. It can learn linear threshold function and can also learn non-linear functions by using the kernel trick. One great property of SVMs is the ability to learn which is independent of the dimensionality of the feature space, because SVMs use support vectors. SVMs also do not require parameter tuning.
Left: Group of dots in different colors on 2D plane. Right: Boundaries identified using SVM to group colored dots.
SVMs work well for text categorization because of these following properties of text: 1) High dimensional input space. SVMs do not depend on the number of features and only use support vectors. This prevents overfitting. 2) Few irrelevant features. Aggressive feature selection may result in loss of information. SVMs can work with very high dimensional feature space. 3) Document vectors are sparse. SVMs work well with problems with dense concepts and sparse instances. 4) Most text categorization problems are linearly separable. These are the theoretical evidence.
The paper used two test collections: the “ModApte” split of the Reuters-21578 database and Ohsumed corpus. SVMs are compared with Naïve Bayes, Rocchio, kNN, and C4.5 Decision Tree. Precision/Recall-Breakeven Point is used as a measure of performance. Experimental results show that SVMs had robust performance improvements over other algorithms. Training using SVMs is slow but classification is very fast. SVMs eliminate the need for feature selection and do not require any parameter tuning.
Video of the Day:
I am not a member of the Mormon church, but I still found this story very moving. It was told by the former LDS Church President Gordon Hinckley. Hope you enjoy it! And may God bless us all if there is a God.
This paper is written by Kamal Nigam, John Lafferty, and Andrew McCallum, all from Carnnegie Mellon University. It was presented at IJCAI-99 workshop on machine learning for information filtering.
This paper talks about the use of maximum entropy techniques for text classification and compares the performance to that of naïve Bayes.
Maximum entropy is a general technique for estimating probability distributions from data. The main principle in maximum entropy is that when nothing is known, the distribution should be as uniform as possible, that is, have maximal entropy. In text classification scenarios, maximum entropy estimates the conditional distribution of the class label given a document. The paper uses word counts as features.
Training data is used to set constraints on the conditional distribution. Maximum entropy first identifies a set of feature functions that will be useful for classification, then for each feature, measures its expected value over the training data and take this to be a constraint for the model distribution.
Improved Iterative Scaling (IIS) is a hillclimbing algorithm for calculating the parameters of a maximum entropy classifier given a set of constraints. It performs hillclimbing in parameter log likelihood space. At each step IIS finds an incrementally more likely set of parameters and converges to the globally optimal set of parameters.
Maximum entropy can suffer from overfitting and introducing a prior on the model can reduce overfitting and improve performance. To integrate a prior into maximum entropy, the paper proposes using maximum a posteriori estimation for the exponential model instead of maximum likelihood estimation. A Gaussian prior is used in all the experiments.
One good thing about maximum entropy is that it does not suffer from any independence assumptions.
The paper used three data sets to compare the performance of maximum entropy to naïve Bayes. The three data sets are WebKB, Industry Sector, and Newsgroups. In WebKB data set, the maximum entropy was able to reduce classification error by more than 40%. For the other two data sets, maximum entropy overfitted and performed worse than naïve Bayes.
Video of the Day:
Liu Qian performing magic tricks at the Chinese New Year Show. Can you figure out how he did the tricks?
This paper was written by Ntoulas (UCLA) and et al. (Microsoft Research) and 15th international conference on World Wide Web, 2006.
This paper is continuing work following two other papers on detecting spam web pages by the same group of authors. It focuses on content analysis as apposed to links. The authors propose 10 heuristics and investigate how well these heuristics correlate with spam web pages using a dataset of 17,168 pages. These heuristics/metrics are then combined as features in addition to 28 others to build a training dataset, so machine learning classifiers can be used to classify spam web pages. Out of the several classifiers experimented, C4.5 decision tree algorithm performed the best, so bagging and boosting are used to improve the performance and the results are reported in terms of accuracy and the precision recall matrix.
The main contributions of this reference paper include detailed analysis of the 10 proposed heuristics and the idea of using machine learning classifiers to combine them in the specific spam web page detection application. Taking advantage of the large web page collection (over 105 million) and a good-sized labeled dataset (17,168 pages), the paper is able to show some nice statistical properties of web documents (spam or non-spam) and good performances of existing classifying methods when using these properties as features of a training set. Not being an export in the IR field, I cannot tell which of the proposed 10 heuristics are novel ideas with respect to spam web page detection. However, fraction of visible content and compression ratio seem to be very creative ideas and look very promising. Using each heuristic by itself does not produce good performance, so the paper combined them into a multi-dimensional feature space. Note here that this method has been used in many research domains with various applications.
One common question IR researchers tend to ask is: how good is your dataset? In section 2, the paper did a good job acknowledging the biases of the document collection and then further provided good justifications. This makes the paper more sincere and convincing. The paper also did a good job explaining things clearly. For instance, in section 4.8, the example provided made it very easy to distinguish “Fraction of page drawn from globally popular words” from “Fraction of globally popular words”. Another example is in section 4.6 when the paper explained how some pages inflated during compression. I specifically liked how the authors explained the concepts of bagging and boosting briefly in this paper. They could have simply directed the readers to the references, but the brief introduction dramatically improves the experience for those readers who have not worked with such concepts (or are rusty on them such as in my case). Although well-written, the paper still has some drawbacks and limitations. Firstly, section 6, related work, should really have been placed right after introduction. That way, readers can get a better picture of how this problem has been tackled in the IR community and also easily see how this paper differs. Also, this section gives a good definition of “content spam”, and it makes much more sense to talk about possible solutions after we have a clear definition.
Secondly, in section 3, the paper talks about 80% of all pages (as a result of uniform random sampling) being manually classified? I strongly suspect that is what the authors meant to say. 80% of over 105 million pages will take A LONG TIME to classify, period! Apparently this collection is not the same DS dataset mentioned in section 4 because the DS dataset only contained pages in English. So what is this collection? It apparently is a larger labeled dataset than the DS dataset. From Figures 6, 8, 10, and 11, we see the line graph touching the x-axis due to possibly not enough data. Using this larger labeled dataset (of the English portion) might have produced better graphs. Another thing I’d like to mention here is that spam web page is a “subjective classification” (at least for me it is). Naturally I’d think the large data collection was labeled under a divide-and-conquer approach, so each document is only looked at by one evaluator. If this were true, then the subjectivity of the evaluators plays an important role on the label. A better approach would have been having multiple evaluators working on the same set of web pages and label following the majority vote to minimize each evaluator’s subjectivity.
Thirdly, when building the training set, the proposed 10 heuristics are combined with 28 other features before applying the classifier. I think it would be better to compare results of using only these 10 features, using only those original 28 features, and using all features combined. That way, we can better evaluate how well these additional 10 heuristics contributed to the improvement of the classifiers.
Additionally, in section 4.1, the paper says “there is a clear correlation between word count and prevalence of spam” according to Figure 4. I failed to see the correlation.
Lastly, the experiment results are only for English web pages. Since the analysis in section 3 (Figure 3) clearly indicate that French and German web pages contained bigger portions of spam web pages, it would be great to see how proposed solution works with those languages. I understand the difficulty of working with other languages, but it would really improve the paper even if only some very initial experiments were performed and results reported.
There are other minor problems with the paper as well. For example, for each heuristic, the paper reported the mode, median, and mean. I think it is also necessary to provide variance (or standard deviation) because it is an important descriptor of a distribution. I would also suggest using a much lighter color so that the line graph is more readable for the portions where it overlaps with the bar graph. Dr. Snell once said that we should always print out your paper in black and white to make sure it looks okay, and I am strong believer of that! Also in section 4.3, the authors meant to say the horizontal axis represents the average “word length” within a page instead of “number of words”.
I think it’s worth mentioning that the authors did an awesome job in the conclusions and future work section. Detecting web spam is really like an “arms race” between the spam filter designers and spammers. As new technologies are developed to filter spam, spammers will always work hard to come up with ways to break the filtering technology. This is an ongoing battle and degradation of the classification performance over time is simply unavoidable.
This is a well-written paper that showed excellent performance, and I certainly enjoyed reading it. I’d like to end this report with a quote directly from the paper which is so well said:
“Victory does not require perfection, just a rate of detection that alters the economic balance for a would-be spammer. It is our hope that continued research on this front can make effective spam more expensive than genuine content.”
I just learned recently that Superman's father is the Godfather!
This paper was written by Cong (Aalborg University) et al. and presented at the 31st annual international ACM SIGIR conference on Research and development in information retrieval, 2008.
Question-Answer System is currently a very hot topic in the IR community and attracted many researchers. This 2004 paper (published in ACM SIGIR’08) is one among many in this area. The problem the paper tries to solve is how to mine knowledge in the form of question-answer pairs specifically from a forum setting. The knowledge can then be used for QA services, to improve forum management, or to augment the knowledge base of chatbot. This is a challenging paper to read because it touches many different concepts and ideas from many research disciplines besides IR such as machine learning (n-fold cross-validation), Information Theory (Entropy), NLP (KL-divergence), Bayesian statistics (Markov Chain Convergence), and Graph Theory (graph propagation).
The main contributions of this reference paper include: 1) a classification-based method for question detection by using sequential pattern features automatically extracted from both questions and non-questions in forums; 2) an unsupervised graph-based propagation approach, which can also be integrated with classification method when training data is available, for ranking candidate answers. The paper also presented a good amount of experimental results including a 2 (datasets) 4 (methods) 3 (measures) design for question detection, a 2 (w. w/o answers) 9 (methods) 3 (measures) design for answer detection, and a 2 (w. w/o answers) 2 (KL convergence or all three) 2 (propagate w. w/o initial score) 3 (measures) design for evaluating the graph-based method, and showed the performance superiority of the proposed algorithm compared to existing methods.
The paper proposed several novel ideas in solving the proposed problem. First, the paper defined support and confidence and also introduced minimum thresholds for both, which are additional constraints previous works did not have. “Minimum support threshold ensures that the discovered patters are general and minimum confidence threshold ensures that all discovered LSPs are discriminating and are cable of predicting question or non-question sentences.” (Quoted from the paper.)
Second, the paper introduced the idea of combining the distance between a candidate answer and the question, and the authority of an author, with KL convergence using a linear interpolation. Because of the specific forum setting, these additional factors improved the algorithm performance. However, note that these additional factors also poses limit to the applicability of the algorithm to other Question-Answer mining applications.
Third, the paper proposed a graph based propagation method that uses a graph to represent inter-relationships among nodes (answers) using generator and offspring ideas to generate edges (weights). With this graph, the paper suggests propagating authority through the graph. The authors argued (briefly) that because this can be treated as a Markov Chain, therefore, the propagation will converge. This idea of using a graph to propagate authority information is great because it takes into consideration of how inter-relationship between pair of nodes can be used to help ranking (following the PageRank idea). The idea of integrating classification (two ways) with graph propagation is another great idea. However, I find this Markovian argument weak. No rationality is given about why this can be treated as a Markovian process, and the transitional probability mentioned is not convincing.
The experiment design in this paper is extremely good. First, when using two annotators to annotate the dataset, the paper created two datasets, the Q-Tunion and Q-TInter and evaluated different algorithms using both datasets. This effectively shows that the algorithms performances showed same trends even with disagreeing annotators. The paper also showed detailed performance comparisons using multiple measures across different datasets and different algorithms/methods. This way, the superiority of the proposed algorithm is clear and convincing.
Additionally, the paper used many good examples in the first half of the paper explain complex concepts or to provide justifications. This is good writing! I wish the paper had done the same thing for the latter part of the algorithm description.
The paper also has some significant drawbacks. First, the paper certainly covered a great deal of information and ideas, especially because of the experiment design, a large amount of performance values are contrasted and analyzed. Even the authors used the phrase “due to space limitations” three times in the paper. It is truly a difficult task to cram everything into 8 pages, which is a constraint for a conference paper. And by doing so, lots of useful information are omitted (e.g. the section about how the Markov process can be justified) and some part of the paper just seemed difficult to understand (section 4.2.2). There are also places where proper references should be given, but are omitted probably due to space limitations (e.g. references for Ripper classification algorithm and power method algorithm). It is probably a better idea to either publish this as a journal paper where more space is available, or write a technical report on this subject and reference to it from this paper.
Second, it also seems that the authors were in a rush to meet the paper deadline. This is shown by the carelessness in many of the math notations used in the paper. For example, the Greek letter λ is used in equations (3), (5), (6), and (10) where they meant different things. The letter ‘a’ used to represent an answer sometimes is bolded and sometimes is italicized when all of them meant the same thing. Recursive updates are also represented using “=” instead of “”, such as in equation (10), and temporal indexes are not used. There are quite a few important spelling errors such as the sentence right after equation (3) where ‘w’ was written as “x”. My personal opinion is that if you are going to put your name on the paper, then better show some professionalism.
Third, the paper proposed a quite complex model with many parameters. Especially, the algorithm used many parameters that were set by empirical results. The author did mention that they did not evaluate different parameter values in one place and discussed the sensitivity of the empirical parameter in another; however, these empirical parameters make one wonder whether the algorithm will generalize well with other datasets or whether these parameters might be correlated in someway. A better approach would probably be either justify qualitatively or quantitively the sensitivity of these empirical parameters by discussing more intuitions behind them or showing experiment results using different values with several datasets of different domains and scale. The paper also proposed a few “magical” equations, such as author(i), equation (10), without rationalize how the formulas came about. (Again, publishing as a journal paper would have lessened such problems.)
There are other minor problems with the paper as well. For example, the paper mentioned several times that the improvements are statistically significant (p-value < 0.001), but without much more detail on how the statistical significances are calculated, I can only assume that they came from the 10-fold cross validation. In my opinion, statistical significance would not be a very good indicator of improvements in such set up. The paper also gave me the impression that they are ranking candidate answers by P(q|a). I would think ranking by P(a|q) would have been more appropriate.
Video of the Day:
Now here are some serious question asking and answering!
This paper was written by Saracevic from Rutgers University and published at the 18th annual international ACM SIGIR conference on Research and development in information retrieval, 1995.
Evaluation metrics are important components of scientific researches. Through evaluation metrics, performances of systems, algorithms, solution to problems can be measured and compared against baselines or among each other. However, what metrics should we use, at what level, and how good are these metrics? Questions like these must be carefully considered. This paper discussed such concerns about past and existing evaluation metrics used in Information Retrieval (IR) and raised many more questions. Please note that this paper was published in 1995 and evaluation metrics/methods in IR have progressed dramatically by now.
This paper is somewhat a survey paper that discussed evaluation metrics used in IR throughout the history and provided many literature references. The main contribution of the paper is that it suggests looking at the evaluation of IR from a much higher perspective, going back to the true purpose of IR, which is to resolve the problem of information explosion. When considering the evaluation of IR systems from this high point, the paper pointed out that there are a lot more to be evaluated besides common/popular evaluation metrics at simply the process level (e.g. Precision and Recall). It urged the IR community to break out of the isolation of single level narrow evaluations.
The author systematically defined six levels of objectives (engineering, input, processing, output, use and user, and social) that need to be addressed in IR systems together with five evaluation requirements (a system with a process, criteria, measures, measuring instruments, and methodology). Then he further discussed in details current practice, potential problems, and needs of evaluation metrics with respect to each of the requirement and how they can be categorized into the six objective levels. This is an excellent way of organizing contents and arguments, which allows the readers to easily see the big picture in a structured framework.
The paper made a strong statement that “both system- and user-centered evaluations are needed” and more efforts are required to allow cooperative efforts of the two orientations, in contrast to the widely proposed shifting from one to the other. This again highlights the author’s suggestion of treating the evaluation of IR as an overall approach.
The author identified many compelling problems and important issues with regard to the evaluation of IR and argued them well. To name a few: Laboratory collections are too removed from reality and TREC has highly unusual composition as to types and subjects of documents and should not be the sole vehicle for IR evaluation. Applying various criteria in some unified manner still poses a major challenge in IR. Assumption of one and only one relevant set as an answer to a request is not warranted. When using relevance as the criterion with precision and recall as the corresponding measures, someone has to judge or establish relevance; the assumption here is that the judgment is reasonable while we know relevance is a very subjective topic.
The paper repeatedly emphasized evaluation of interaction between users and IR systems as an integral part of the overall evaluation. In recent years, there’s also a strong trend showing more and more researchers in various areas interested in understanding how the human factors and the interaction between human and machines (robots) play an important role in the performance of systems. A good example is the emergence of Human Robot Interaction (HRI). Therefore, this topic deserves a separate discussion here. The ultimate goal of an IR system is to serve human. If information retrieved is not presented to the user correctly, then the IR system fails miserably. Also because of the subjectivity (with respect to an individual user) and ambiguity (such as query term meanings) of IR, multiple rounds of interaction between the user and the IR system can dramatically improve the performance of information retrieval. One example would be retrieving documents related to the query term “Python”. An interactive IR system can further allow the user to specify if he/she wants to retrieval information about the animal or the programming language. As stated in the paper, interactions in IR were extensive studied and modeled, however, interactivity plays no role in large evaluation projects (which I believe is still true even up to today). Granted that it is difficult to come up with sound evaluation metrics for interactivity, more discussion and research in this area is definitely very necessary.
This paper certainly has its shortcomings. First of all, the author could certainly have been more concise in the writing. Additionally I found the comparisons using expert systems and OPAC to be distracting from the main ideas and do not contribute much to the arguments. Eliminating them would have made the paper more focused.
Granted that precision and recall are used as the main evaluation metrics to measure relevance in the system and process level, many other evaluation metrics also existed but were not covered in this paper. Examples include (but not limited to) F-measure, Entropy, Variation of Information, Adjusted Rand Index, V-Measure, Q-2, Log likelihood of the data, etc. Besides quantitive evaluation metrics, qualitative analysis is also a common tool people use to evaluate performances of IR systems, and the paper didn’t touch this subject at all.
The paper argued that it is a problem that “every algorithm and every approach anywhere, IR included, is based on certain assumptions” and these assumptions could have potential negative effects. I found this argument weak and not well constructed. It is true that when researches design algorithms or model problems they make assumptions. Good researchers clearly identify these assumptions in their publications and analyze the potential effects these assumptions have on their algorithms or their models. Sometimes assumptions are made without sound reasons but are justified by good performances from real applications/data. It is almost unavoidable to make various assumptions when we do research. We should not be afraid of making assumptions, but be careful about our assumptions and justify for them.
Lastly, there is one more important drawback of this paper. It did a good job identifying many problems and issues regarding evaluations in IR. However, it did a poor job providing constructive ideas and suggestions to many of these problems. I am not suggesting the author should find solutions to many of these problems, but some initial ideas or thoughts (let it be throw-away or naïve ideas) would have improved the paper considerably.
In summary, the paper succeeded in bringing attentions to treating evaluation in IR from a much higher perspective and also provided good description, references, and discussion for the “current” state (up to 1995) of evaluation metrics in IR. I enjoyed reading this paper.
Video of the Day:
If you have a Toyota, take it in for a check, because it might be a matter of life and death for you and your family!
This paper was written by Baker from Carnegie Mellon and McCallum from Justsystem Pittsburgh Research Center, published at 21st annual international ACM SIGIR conference on Research and development in information retrieval, 1998.
This paper applies Distributional Clustering to document classification. Distributional Clustering can reduce even space by joining words that induce similar probability distributions among the target features that co-occur with the words in questions. Word similarity is measured by the distributions of class labels associated with the words in question.
The three benefits of using word clustering are: useful semantic word clusterings, higher classification accuracy, and smaller classification models.
The paper first went over the probabilistic framework and Naïve Bayes, and then suggests using weighted average of the individual distributions as the new distribution. Kullback-Leibler divergence, an information-theoretic measure that can be used to measure difference between two probability distributions is introduced, and then the paper uses “KL divergence to the mean”. Instead of compressing two distributions optimally with their own code, the paper uses the code that would be optimal for their mean. Assuming a uniform class prior, choosing the most probable class by naïve Bayes is identical to choosing the class that has the minimal cross entropy with the test document. Therefore, when words are clustered according to this similarity metric, increase in naïve Bayes error is minimized.
The algorithm works as the following: The clusters are initialized with the M words that have the highest mutual information with the class variable. The most similar two clusters are joined, then the next word is added as a singleton cluster to bring the total number of clusters back up to M. This repeats until all words have been put into one of the M clusters.
The paper uses three real-world text corpora: newswire stores, UseNet articles and Web pages. Results show that Distributional Clustering can reduce the feature dimensionality by three orders of magnitude, and lose only 2% accuracy.
Distributional Clustering performs better than feature selection because merging preserves information instead of discarding it. Some features that are infrequent, but useful when they do occur, get removed by the feature selector; feature merging keeps them.
I have a dream that one day when I get old, there will be intelligent robots to take care of people like me, so we can enjoy life freely, happily, and independently.
This paper is written by Yiming Yang from Carnnegie Mellon University and Jan O. Pedersen from Verity, Inc. presented at ICML 97 (International Conference on Machine Learning). It has been cited 2742 times according to Google Scholar, another seminal paper indeed!
This paper evaluates and compares five feature selection methods: document frequency (DF), information gain (IG), mutual information (MI), a χ2-test (CHI), and term strength (TS).
A major difficulty of text categorization is the high dimensionality of the feature space. Automatic feature selection methods include the removal of non-informative terms according to corpus statistics, and the construction of new features which combine lower level features into higher-level orthogonal dimensions.
Document frequency is the number of documents in which a term occurs. Terms with low document frequency (less than a threshold) were removed from the feature space with the assumption that rare terms are either non-informative for category prediction or not influential in global performance. Information gain measures the number of bits of information obtained for category prediction by knowing the presence or absence of a term in a document. Terms whose information gain was less than threshold were removed from the feature space. Mutual information becomes zero if the term t and category c are independent. A weakness of mutual information is that the score is strongly influenced by the marginal probabilities of terms. The χ2 statistic measures the lack of independence between t and c, and it is known not to be reliable for low-frequency terms. Term strength method estimates term importance based on how commonly a term is likely to appear in “closely-related” documents and is based on document clustering. Average number of related documents per document is used in threshold tuning.
The paper used kNN and LLSF because: both are top-performing, state-of-the-art classifier, both scale to large classification problems, both are a m-ary classifier providing a global ranking of categories given a document, both are context sensitive, and the two classifiers differ statistically. The Reuters-22173 collection and the OHSUMED collection were used for the experiments and recall and precision are used as performance measures.
Experiments include using full vocabulary to removing 98% of the unique terms. Results show that IG and CHI are most effective in aggressive term removal. DF is comparable to IG and CHI with up to 90% term removal. TS is comparable with up to 50-60% term removal. MI has inferior performance due to a bias favoring rare terms and a strong sensitivity to probability estimation errors. Results also show strong correlation among DF, IG and CHI scores.
This paper is written by Andrew McCallum (Just Research) and Kamal Nigam (Carnegie Mellon University) and published at an AAAI-98 workshop on learning for text categorization. This is a seminal paper cited by 1426 papers according to Google Scholar!
Two text classification approaches, the multi-variate Bernoulli model and the multinomial model, both use the naïve Bayes assumption. This paper tries to differentiate the two models and compare their performances empirically on five text corpora.
In text classification, a naïve Bayes classifier assumes that the probability of each word occurring in a document is independent of the occurrence of other words in the document and is independent of the word’s context and position in the document. This assumption simplifies learning dramatically when the number of attributes (features) is large. Both approaches use training data to calculate estimates of the generative model and then uses Bayes’ rule to calculate the posterior probability of each class given the evidence of the test document. Then the class most probable is selected.
One major difference between these two approaches is that the multi-variate Bernoulli model doesn’t care about word frequency in documents, while the multinomial model does. Another difference is that the multi-variate Bernoulli model explicitly includes the non-occurrence probability words that do not appear in the document.
When selecting features, in order to reduce vocabulary size, only words that have the highest average mutual information with the class variable are kept. Average mutual information is the difference between the entropy of the class variable and the entropy of the class variable conditioned on the absence or presence of the word.
Five text corpora are used and they are Yahoo! ‘Science’ hierarchy, Industry Sector, Newsgroups, WebKB, and Reuters. Empirical results show that the multi-variate Bernoulli model works well with small vocabulary sizes, but the multinomial model performs better at larger vocabulary sizes. The multinomial model produced on average a 27% reduction in error over the multi-variate Bernoulli model at any vocabulary size.
The boringness of a paper is inverse proportional to the amount of time it takes to put the reader to sleep.
Video of the Day:
You have to watch past 0:40 to really appreciate it! It's an LCD!
This paper is written by researchers at Brown University and published at UIST'98.
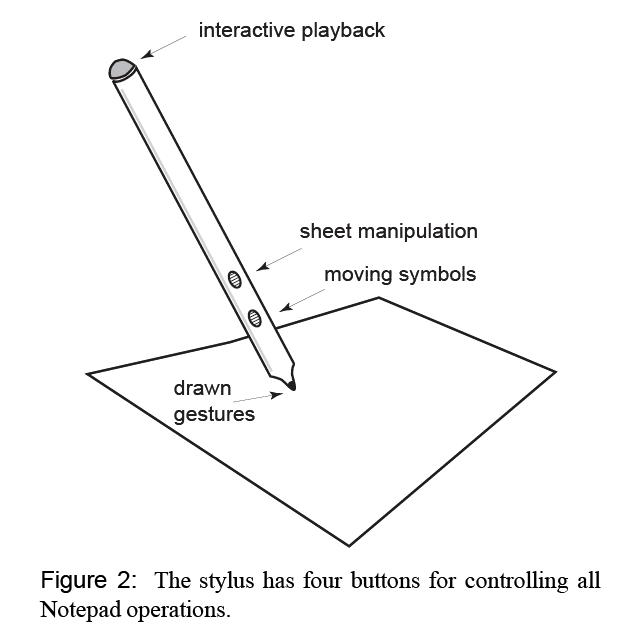
Notating music can be done with a common UI with windows, icons, menus, and point-and-click (WIMP) such as those used in popular software synthesizers and editing tools (e.g. Cakewalk). However, the user model of using paper and pencil is very different and is more desirable because of the simplicity. This paper presents a system that allows the musicians to create music notation directly using a stylus on a Tablet PC.
The system described in this paper followed some previous work from Buxton, but added more features. The notation system allows the drawing of: notation symbols, Beams, Accidentals, Clefs and key signatures. Editing included region selection (lasso), copying, pasting, and deleting (scribble or text editing type delete gesture). The user can also assign instrument and view more of the music score using a perspective wall metaphor.
The authors developed an alternate method for entering notes by "scribbling in" a notehaed. This is different from Buxton's gestures (which had bad user experiences). This allowed accurate placement of symbols because an average position is used. This is also natural to the user because that's how they do it on paper. However, this method could be slower than point and click and also does nto convey the note duration. The video below shows how the system works.
To evaluate the system, the authors asked some users to try the system and then performed some informal interviews.
What's great about this paper is that it is the first in using gesture recognition to tackle the problem mentioned. The weak spot of the paper is its evaluation. If a more formal user study is performed to specifically measure certain aspects of the user performances by comparing old vs. new systems, the results would be more convincing. On a side note, the paper mentioned about estimating probability of posted tokens. I wish the paper had discussed more about how probability is calculated.
You can follow this link to read more about this project at Brown University.
In my humble opinion, a good UI is one where there’s minimal amount of learning/training/practicing involved. To the user it almost seems that all the designs are natural and logical conclusions (based on normal experiences of a standard user – with a certain profession or within a certain era). There might be better and more efficient ways (e.g. I can type a lot faster than write, and my handwriting is ugly), however, it might take a lot of training and practice in order to achieve the efficiency. In such cases, the best thing to do is probably to give the user the options so he/she can pick the way he/she wants it. Some incentives (with proper tutorials and demos) might be helpful to try to persuade the user to move toward the more efficient method, so he/she will endure the (maybe painful or dull) training and practice for higher efficiency. The important point is to let the user make the decision himself/herself. A forceful push toward the new method will only generate resentment (e.g. Windows Vista).
A user judges a solution based on how easy it is to to use, not how great the designer thinks it is.